SubQ AI : l'alternative à Claude qui te facture 5 % du prix
Une startup de 30 personnes vient de sortir un modèle avec 12 M de tokens de contexte (12× Claude Opus) pour environ 5 % du prix. API drop-in, zéro migration.
SubQ AI : l'alternative à Claude qui te facture 5 % du prix
Pour qui ? Tu utilises Claude / GPT / Gemini en production (chatbot, agent, génération de contenu, code), et chaque mois ta facture API te pique un peu plus. Cette ressource te donne le contexte, les chiffres et la marche à suivre pour tester l'alternative qui fait du bruit en ce moment.
Une startup de 30 personnes vient de publier un modèle qui — sur le papier — rend Claude, GPT et Gemini beaucoup moins évidents à choisir.
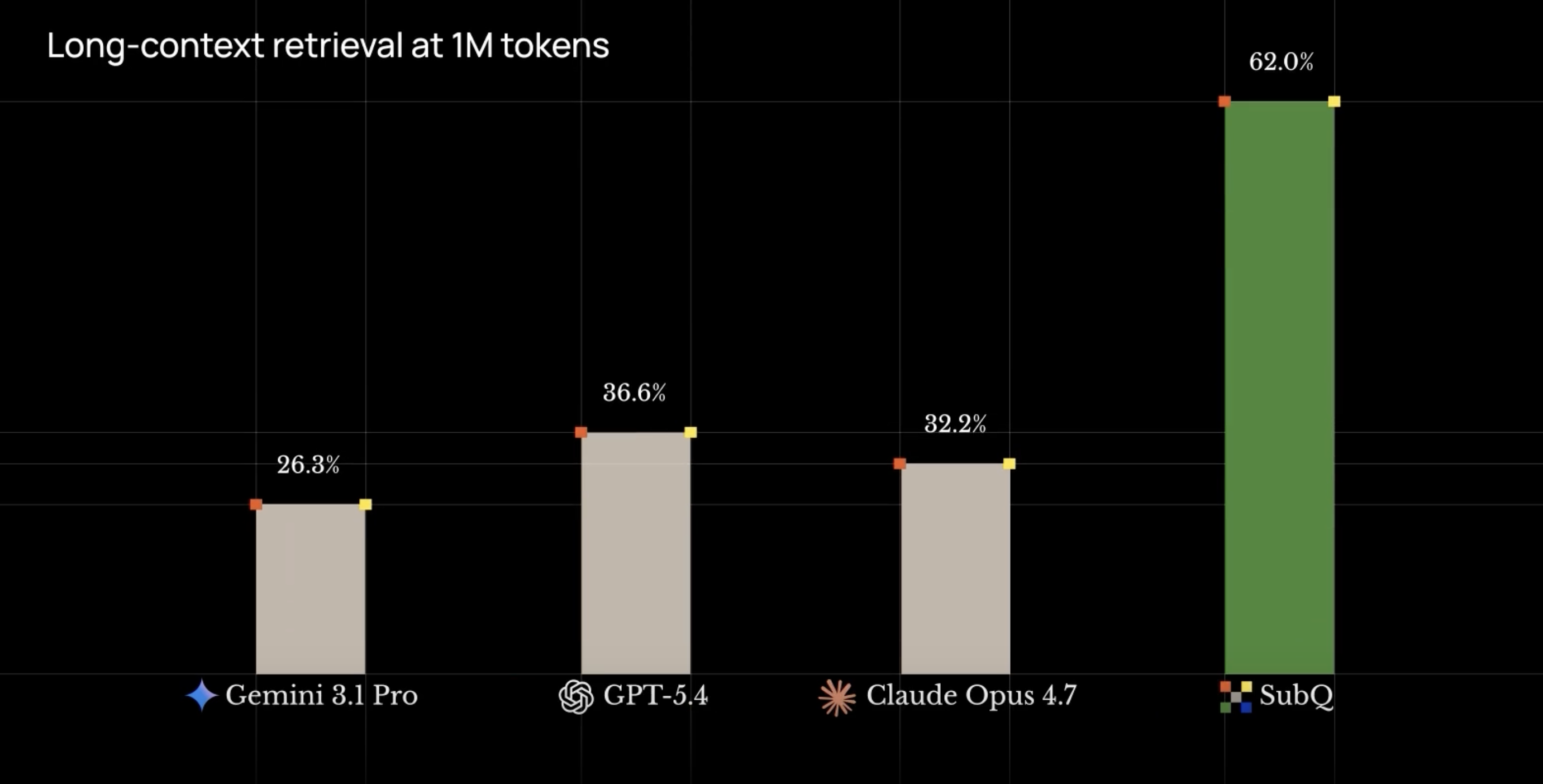
Les trois chiffres qui résument la promesse :
- 12 M tokens de contexte (vs 1 M pour Claude Opus en mode étendu)
- 5 % du prix de Claude à usage équivalent
- Zéro migration : API OpenAI-compatible, tu changes l'URL et la clé, c'est fini
Le produit s'appelle SubQ AI (subq.ai). Voici ce qu'il faut savoir avant d'aller t'inscrire à la bêta — et ce qu'il faut tester pour valider si ça tient la route sur tes use-cases.
1. Ce que SubQ revendique
Une fenêtre de contexte de 12 M tokens
| Modèle | Contexte max |
|---|---|
| Claude Opus 4.7 (1M context) | 1 000 000 tokens |
| GPT (frontier OpenAI) | 200 000 – 1 000 000 tokens selon le palier |
| Gemini 2.x Pro | 1 000 000 – 2 000 000 tokens |
| SubQ AI | 12 000 000 tokens |
Concrètement : tu peux balancer une codebase entière + 50 PDFs en un seul prompt, sans router, sans RAG maison, sans chunking. C'est la différence entre « je dois construire un pipeline de retrieval » et « je colle tout, je pose ma question ».
~5 % du prix de Claude
Le pitch parle d'un rapport ~1 à 20 sur le même volume de tokens. L'exemple montré dans leur teaser :
| Task | Claude Opus | SubQ AI |
|---|---|---|
| Codebase entière + 50 PDFs, un seul prompt | ~200 € | ~10 € |
À vérifier sur tes propres workloads : la grille tarifaire publique ne sera publiée qu'à la sortie de bêta. En attendant, le ratio annoncé tient lieu de promesse marketing — c'est ce que tu valides en test.
API drop-in, zéro migration
SubQ expose une API OpenAI-compatible. Côté code, ça veut dire :
# Ce que tu faisais avec OpenAI / Anthropic
export OPENAI_API_KEY=sk-...
export OPENAI_BASE_URL=https://api.openai.com/v1
# Bascule vers SubQ
export OPENAI_API_KEY=sk-subq-...
export OPENAI_BASE_URL=https://api.subq.ai/v1
Aucun changement de code côté client si tu utilises déjà le SDK OpenAI (ou un wrapper compatible comme Vercel AI SDK, LangChain, LlamaIndex…). Tu changes l'URL et la clé, point.
Une CLI pour les builders
Leur démo montre une commande locale :
builder@local $ subq chat --context ./codebase ./docs/*.pdf
✓ Context loaded: 12 000 000 tokens
✓ API key detected (OpenAI-compatible)
✓ Zero migration required
> Ready. Send your prompt.
Et — c'est probablement le plus parlant pour les utilisateurs de Claude Code — une commande explicite pour basculer :
dev@studio $ subq code --replace claude-code
↳ Replacing Claude Code with SubQ...
✓ Same workflow. Same power.
✓ Cost reduction: -95%
2. À quoi ça sert (réellement)
Un modèle « long contexte + pas cher », c'est deux nouveaux use-cases qui deviennent économiquement viables :
- Agents qui bouffent du contexte massif — RAG sur 10K pages, audit de codebase complète, analyse longitudinale de logs, due diligence sur des centaines de docs. Aujourd'hui tu fais du chunking pour que ça rentre ; demain tu colles tout.
- Agents qui tournent souvent — copilots internes, génération de contenu à la chaîne, classification massive. Le -95 % de coût change l'équation : tu peux laisser tourner ce qui était trop cher pour exister.
Les use-cases où ça ne change rien :
- Chat grand public type ChatGPT : le contexte de 1 M tokens suffit largement.
- Tâches « haut niveau de raisonnement » sur petit prompt : ce qui compte là c'est la qualité du modèle, pas la fenêtre. À tester sur des benchmarks que tu maîtrises.
3. Comment rejoindre la bêta
Étape 1 — Demander l'accès
- Va sur subq.ai/request-early-access
- Renseigne ton email pro + un use-case concret (1-2 lignes)
- Tu reçois la clé API et l'URL d'accès dans les jours qui suivent
Le pitch parle d'une fenêtre étroite : early adopters = milliers d'€ économisés sur la prochaine année d'API. Plus tu attends, plus le prix bêta se rapproche du prix public (qui n'est pas encore annoncé mais sera mécaniquement plus haut).
Étape 2 — Brancher en 2 minutes
Dans ton .env (ou tes variables Vercel / Railway / fly.io) :
OPENAI_API_KEY=<ta clé SubQ>
OPENAI_BASE_URL=https://api.subq.ai/v1
# Optionnel : pin un modèle spécifique
OPENAI_MODEL=subq-1
Si tu utilises le SDK Anthropic directement (pas le SDK OpenAI), il faudra basculer ton code sur le SDK OpenAI — c'est une migration de 30 minutes pour un projet moyen :
// Avant
import Anthropic from "@anthropic-ai/sdk";
const client = new Anthropic();
// Après
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
baseURL: process.env.OPENAI_BASE_URL,
});
Étape 3 — Tester sur un workload réel
Ne te contente pas du prompt de démo. Lance les 3 tests qui comptent :
| Test | Pourquoi |
|---|---|
| Ton prompt de prod le plus fréquent | Tu compares la qualité côte à côte avec Claude / GPT sur ce que ton produit fait vraiment |
| Un prompt long-contexte (≥ 500K tokens) | Tu valides que les 12 M ne sont pas qu'un chiffre de pitch et que la qualité tient sur du long |
| Un batch de 100 requêtes en parallèle | Tu mesures la latence p95 et le throughput — c'est ce qui te coûte en prod |
4. Le piège à éviter
Les « alternatives moins chères » sortent toutes les 2 mois. Ce qui les disqualifie en général, c'est un (ou plusieurs) des points suivants :
- Qualité en chute sur les tâches complexes (raisonnement multi-étapes, code)
- Latence imprévisible sous charge
- Données envoyées vers une juridiction problématique pour ton métier (RGPD, secret pro, etc.)
- Pas de support ou un SLA fantôme
Pour SubQ : tant que le produit est en bêta, considère que tu testes, pas que tu remplaces. Garde Claude ou GPT en fallback dans ton code (la lib openai supporte plusieurs clients en parallèle, switch trivial). Tu bascules le trafic progressivement : 5 % → 25 % → 100 % une fois que tu as des métriques sur 2 semaines de prod.
✅ Checklist pour évaluer SubQ proprement
- Inscription à la bêta sur
subq.ai/request-early-access - Clé API + URL reçues, ajoutées en variable d'env
- 1er prompt envoyé via CLI (
subq chat ...) — la commande renvoie quelque chose de cohérent - Bascule de 5 % du trafic prod vers SubQ (feature flag ou A/B test côté serveur)
- 2 semaines de logs comparés : qualité, latence p95, coût réel facturé
- Décision : on monte à 100 %, on reste à 5 % pour les longues requêtes, ou on abandonne
💰 Pourquoi l'arbitrage est ouvert maintenant
L'économie d'un produit IA en early bêta :
| Période | Pricing typique | Effort |
|---|---|---|
| Bêta privée | Très subventionné (gratuit ou -95 % du prix marché) | Inscription manuelle |
| Bêta publique | Marges plus serrées (~-50 % du prix marché) | Inscription self-serve |
| GA | Prix de marché — l'économie disparaît | Aucun |
SubQ est en bêta privée. C'est exactement la fenêtre où l'arbitrage existe. Quand le produit passe en GA (general availability), les conditions ne sont plus les mêmes — c'est de la mécanique de marché, pas du FOMO.
Un build qui consomme 2 000 €/mois d'API aujourd'hui → ~100 €/mois sur SubQ si les chiffres tiennent. Sur 12 mois, ça paie un dev junior à mi-temps.
🚨 À savoir
- Ce n'est pas un endorsement. Le pitch est solide, les chiffres annoncés sont impressionnants, mais aucun benchmark indépendant publié à date. Teste avant de basculer.
- API compatible OpenAI ≠ comportement identique. Les modèles ont chacun leurs tics : un prompt parfaitement réglé pour Claude peut sous-performer sur SubQ et inversement. Compte 1-2 jours pour re-tuner tes prompts critiques.
- Sécurité / conformité. Avant de balancer des données clients, vérifie la juridiction des serveurs, la politique de rétention, et si SubQ peut signer un DPA si tu es soumis au RGPD.
- Pas de claude-code 1:1. La commande
subq code --replace claude-codeest leur framing marketing — en pratique, c'est un agent CLI de leur côté, pas un fork de Claude Code. Le workflow ressemble, l'écosystème (skills, MCP, hooks) n'est pas le même.
Lien direct pour rejoindre la bêta : subq.ai/request-early-access
Questions sur la migration ou l'évaluation ? DM Instagram, je t'aide à monter ton test A/B.